Hi @fivefilters ,
last week I wanted to upgrade my Debian server from bullseye to bookworm which results in a disaster, so I needed to reinstall the complete machine. But now I installed Trixie (current testing branch). Fortunately I had recent backups of most of my tools.
After installing apache, php and some modules I ran into an error with faz.net (single articles and feed URL). While ftr.fivefilters.net works well I got error with the same site_config on my self-hosted 3.9.13 I think that some component is missing OR something is too new because of deprecation warnings.
How can I solve this problem? I want to be sure, before trying to downgrade php.
Example-URL:
www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html
* APC is disabled or not available on server
* Supplied URL: https://www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html
* ** Loading class HumbleHttpAgent (humble-http-agent/HumbleHttpAgent.php)
* ** Loading class ContentExtractor (content-extractor/ContentExtractor.php)
* ** Loading class SiteConfig (content-extractor/SiteConfig.php)
* --------
* Attempting to process URL as feed
* ** Loading class SimplePie_HumbleHttpAgent (humble-http-agent/SimplePie_HumbleHttpAgent.php)
* ** Loading class DisableSimplePieSanitize (DisableSimplePieSanitize.php)
* Fetching URL (https://www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html)
* Starting parallel fetch (curl_multi_*)
* Processing set of 1
* ...https://www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html
* ......adding to pool
* . looking for site config for faz.net in custom folder
* . looking for site config for faz.net in standard folder
* ... found site config in standard folder (faz.net.txt)
* Cached site config with key faz.net
* Cached site config with key faz.net.merged
* Checking fingerprints...
* No fingerprint matches
* . looking for site config for global in custom folder
* . looking for site config for global in standard folder
* ... found site config in standard folder (global.txt)
* Cached site config with key global
* Cached site config with key global.merged.ex
* Appending site config settings from global.txt
* ......user-agent set to: PHP/7.4
* ......referer set to: http://www.google.co.uk/url?sa=t&source=web&cd=1
* Sending request...
* Received responses
* ... site config for faz.net.merged already loaded in this request
* Checking fingerprints...
* No fingerprint matches
* ... site config for global.merged.ex already loaded in this request
* Appending site config settings from global.txt
* --------
* Constructing a single-item feed from URL
* ** Loading class FeedWriter (feedwriter/FeedWriter.php)
* --------
* Fetching feed items
* Starting parallel fetch (curl_multi_*)
* Processing set of 1
* ...https://www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html
* ......in memory
* --------
* Processing feed item 1
* Item URL: https://www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html
* ** Loading class FeedItem (feedwriter/FeedItem.php)
* URL already fetched - in memory (https://www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html, effective: https://www.faz.net/aktuell/wirtschaft/klima-nachhaltigkeit/eilantrag-gegen-novelle-des-klimaschutzgesetzes-19675618.html)
* Character encoding: utf-8
* Looking for site config files to see if single page link exists
* ... site config for faz.net.merged already loaded in this request
* Checking fingerprints...
* No fingerprint matches
* ... site config for global.merged.ex already loaded in this request
* Appending site config settings from global.txt
* ** Loading class Readability (readability/Readability.php)
<br />
<b>Deprecated</b>: mb_convert_encoding(): Handling HTML entities via mbstring is deprecated; use htmlspecialchars, htmlentities, or mb_encode_numericentity/mb_decode_numericentity instead in <b>/var/www/foo/ftr/libraries/readability/Readability.php</b> on line <b>145</b><br />
* --------
* Attempting to extract content
* ... site config for faz.net.merged already loaded in this request
* Checking fingerprints...
* No fingerprint matches
* ... site config for global.merged.ex already loaded in this request
* Appending site config settings from global.txt
* Strings replaced: 0 (find_string and/or replace_string)
* Attempting to parse HTML with html5php
* ** Loading class Masterminds\HTML5 (html5php/HTML5.php)
* Title matched: Eilantrag gegen Novelle des Klimaschutzgesetzes
* ...XPath match: //meta[@property="og:title"]/@content
* Language matched: de
* Extracting Open Graph elements
* Extracting Twiter Card elements
* Stripping 1 elements (strip: //img[@width='1'])
* Stripping 9 elements (strip: //img/@width)
* Stripping 9 elements (strip: //img/@height)
* Stripping 1 elements (strip_id_or_class: invisible)
* Stripping 20 elements with inline display:none style
* JSON+LD: found script tag
* JSON+LD: found date: 2024-04-24
* JSON+LD: found author(s): Katja Gelinsky
* Using Readability
* Detecting body
* Done!
APC is not available at the moment, I need to install or activate this in php. But on my testing installation (for developing site-configs) APC is set to OFF anyway with same error.
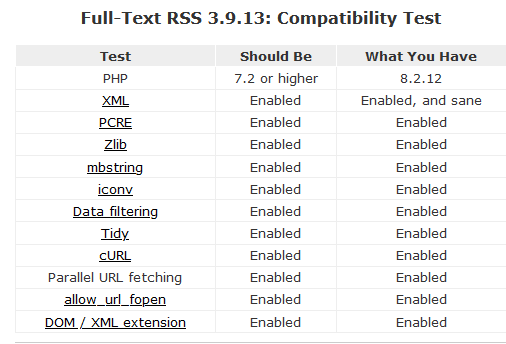
P.S. current site config for faz.net is obsolete in some/many selectors, due to new design. I already was working on that before the crash.
Hi @HolgerAusB,
There were unfortunately PHP 8.2 compatibility changes that we missed. I think there are only two places you need to update to fix this:
libraries/readability/Readability.php
Line 145 of Readability.php (file referenced in your error) contains a conversion call that’s deprecated in PHP 8.2:
$html = mb_convert_encoding($html, 'HTML-ENTITIES', "UTF-8");
Replace with:
$html = mb_encode_numericentity($html, [0x80, 0xFFFF, 0, 0xFFFF], 'UTF-8');
libraries/readability/JSLikeHTMLElement.php
Line 59 of JSLikeHTMLElement.php is:
$value = mb_convert_encoding($value, 'HTML-ENTITIES', 'UTF-8');
Replace with:
$value = mb_encode_numericentity($value, [0x80, 0xFFFF, 0, 0xFFFF], 'UTF-8');
Please post again if you still have trouble.
2 Likes
hmm, now I ran unto the next problem which (I think) is php8.2 dependend.
www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time
This works fine on ftr.fivefilters.net which is interesting, because none of the body-selectors exists in html. But it is a JavaScript site.
I got no result on my 3.9.13: [unable to retrieve full-text content]
After setting a body: //main[1] which works with wallabagger for wallbag, I got a yellow error for php8.2 (and php8.1):
<b>Warning</b>: Attempt to read property "nodeType" on null in <b>/var/www/.../ftr/libraries/content-extractor/ContentExtractor.php</b> on line <b>864</b><br />
So I reverted the patch and installed multiple php versions: 8.3, 8.2, 8.1 and 7.4 including all modules named in ftr_compatibility_test.php
and set the version in apaches fulltextrss.conf, e.g.:
<FilesMatch \.php$>
# For Apache version 2.4.10 and above, use SetHandler to run PHP as a fastCGI process server
SetHandler "proxy:unix:/run/php/php7.4-fpm.sock|fcgi://localhost"
</FilesMatch>
With 7.4 I only get the lead image, which I think is autodetected from the head/meta. But no text at all.
I think there might be new code in 3.10 which is doing that magic?
Here the debug of 8.2 with my new body selector
* APC is disabled or not available on server
* Supplied URL: https://www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time
* ** Loading class HumbleHttpAgent (humble-http-agent/HumbleHttpAgent.php)
* ** Loading class ContentExtractor (content-extractor/ContentExtractor.php)
* ** Loading class SiteConfig (content-extractor/SiteConfig.php)
* --------
* Attempting to process URL as feed
* ** Loading class SimplePie_HumbleHttpAgent (humble-http-agent/SimplePie_HumbleHttpAgent.php)
* ** Loading class DisableSimplePieSanitize (DisableSimplePieSanitize.php)
* Fetching URL (https://www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time)
* Starting parallel fetch (curl_multi_*)
* Processing set of 1
* ...https://www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time
* ......adding to pool
* . looking for site config for bbc.com in custom folder
* ... found site config (bbc.com.txt)
* Cached site config with key bbc.com
* . looking for site config for bbc.com in standard folder
* ... site config for bbc.com already loaded in this request
* . merging config files
* Cached site config with key bbc.com.merged
* Checking fingerprints...
* No fingerprint matches
* . looking for site config for global in custom folder
* . looking for site config for global in standard folder
* ... found site config in standard folder (global.txt)
* Cached site config with key global
* Cached site config with key global.merged.ex
* Appending site config settings from global.txt
* ......user-agent set to: PHP/7.4
* ......referer set to: http://www.google.co.uk/url?sa=t&source=web&cd=1
* Sending request...
* Received responses
* ... site config for bbc.com.merged already loaded in this request
* Checking fingerprints...
* No fingerprint matches
* ... site config for global.merged.ex already loaded in this request
* Appending site config settings from global.txt
* --------
* Constructing a single-item feed from URL
* ** Loading class FeedWriter (feedwriter/FeedWriter.php)
* --------
* Fetching feed items
* Starting parallel fetch (curl_multi_*)
* Processing set of 1
* ...https://www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time
* ......in memory
* --------
* Processing feed item 1
* Item URL: https://www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time
* ** Loading class FeedItem (feedwriter/FeedItem.php)
* URL already fetched - in memory (https://www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time, effective: https://www.bbc.com/worklife/article/20200121-why-procrastination-is-about-managing-emotions-not-time)
* Character encoding: utf-8
* Looking for site config files to see if single page link exists
* ... site config for bbc.com.merged already loaded in this request
* Checking fingerprints...
* No fingerprint matches
* ... site config for global.merged.ex already loaded in this request
* Appending site config settings from global.txt
* --------
* Attempting to extract content
* ... site config for bbc.com.merged already loaded in this request
* Checking fingerprints...
* No fingerprint matches
* ... site config for global.merged.ex already loaded in this request
* Appending site config settings from global.txt
* Strings replaced: 1 (find_string and/or replace_string)
* Attempting to parse HTML with html5php
* ** Loading class Readability (readability/Readability.php)
* ** Loading class Masterminds\HTML5 (html5php/HTML5.php)
* Title matched: Why procrastination is about managing emotions, not time
* ...XPath match: //meta[@property="og:title"]/@content
* Extracting Open Graph elements
* Extracting Twiter Card elements
* Body matched
* ...XPath match: //main[1]
* JSON+LD: found script tag
* JSON+LD: found date: 2020-05-14
* JSON+LD: found author(s): Christian Jarrett
<br />
<b>Warning</b>: Attempt to read property "nodeType" on null in <b>/var/www/.../ftr/libraries/content-extractor/ContentExtractor.php</b> on line <b>864</b><br />
* Done!
Hi Holger, we recently added special handling for BBC and a couple of other sites to our hosted service. These produce their content as JSON, rather than HTML, so we cannot use site config files. The extraction code for these will be in version 4 of Full-Text RSS which we’re testing. Will likely have an alpha release in May. I assume it works with Wallabager because the content is being sent after Javascript execution, am I right? With Full-Text RSS, to do that we’d have to rely on a headless browser. That process is too heavy for the number of requests the service gets, so we have to extract from JSON if we can.
1 Like
Good to hear that. So there is no component missing on my installation.
Wallabager browser plugin is doing the same as P2K plugin, yes. Catching the code after Java processing.
I began to write a new site-config to work with wallabager/wallabag. I am a bit afraid, if this could break things with FTR. Should I just upload the new config or would you like to test it before?
@fivefilters could you please check my patch in bbc.com.txt if this breaks the service on ftr.fiverfilters.org|net before I commit that to the repo?
github.com/HolgerAusB/ftr-site-config/blob/bbc.com/bbc.com.txt
it is needed for e.g.:
@HolgerAusB Sorry for the slow reply. This looks good to me!
1 Like
