@fivefilters: In addition to this I could not manage to get the in-article image of a different source with Fulltext-RSS while Wallabag gets it. It is an ordinary <figure><div><div><div><img...> combination. But the <img> is striped from fulltext, while the <figure> and <div> tags remain.
test_url: Zelená energie na úkor lesa. V Bavorsku řeší dilema s větrníky - Seznam Zprávy

and
test_url: Svět je čím dál horší, shodli se všichni. Ale vědci ukazují, že jde o iluzi - Seznam Zprávy

Hi @HolgerAusB, I had a look and the problem is that the images here appear inside <noscript> elements, and in the site config, you are stripping <noscript> elements. To see this you have to examine the HTML returned by the server, not after browser rendering. If you use developer tools (like in my screenshot below), you’ll need to disable javascript in developer tools first (in Firefox you can press F1 and then check the ‘Disable Javascript’ checkbox).
HTML as sent by server
The image above is a representation of the HTML the server returns, prior to your browser executing Javascript to add/remove elements. If you use developer tools with Javascript enabled (which is the case normally), you’ll see the HTML looks different:
HTML after browser executes Javascript (<img> tag has been inserted above <noscript>)
When Full-Text RSS makes requests to get HTML, it doesn’t execute any Javascript, so you get the HTML in the first image, and then the image is stripped because of the strip: //noscript rule. For sites like this, we usually use string replacement to replace the <noscript> with <div>:
# remove noscript
replace_string(<noscript>): <div>
replace_string(</noscript>): </div>
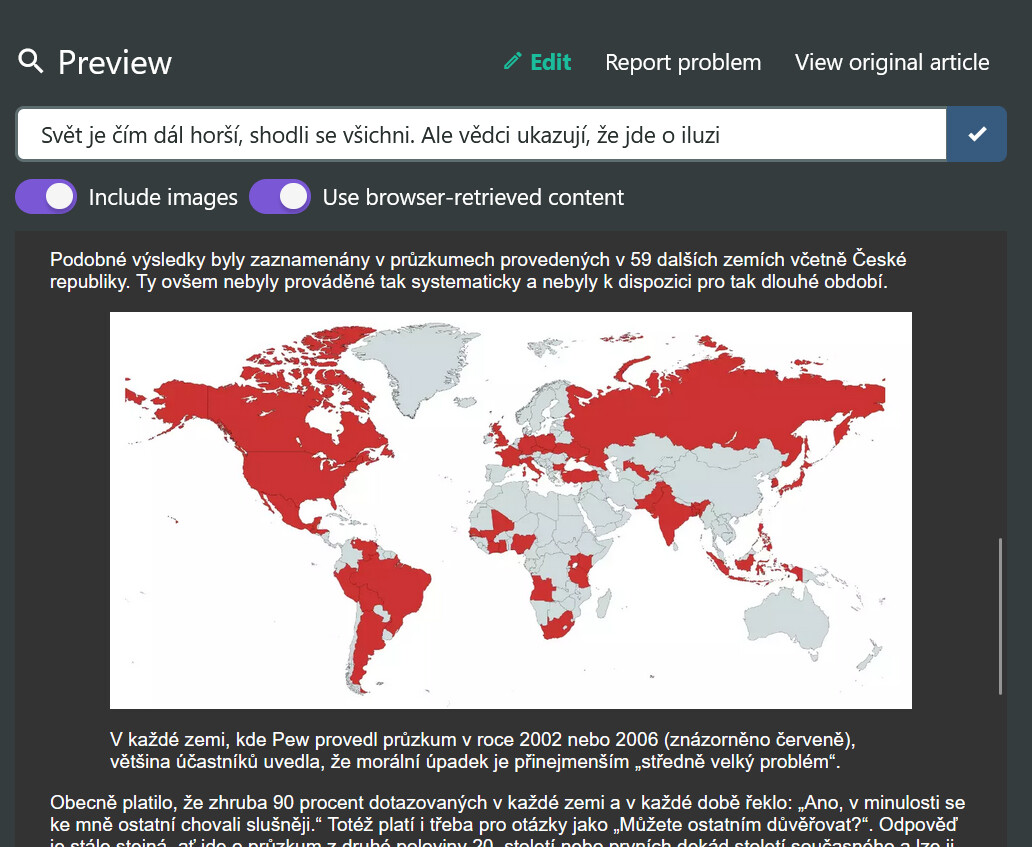
But the tricky part here is we’re assuming the software that uses these rules (e.g. Full-Text RSS) is getting the HTML prior to Javascript rendering. That’s not always the case. For example, users of Push to Kindle’s browser extensions get the HTML sent to Full-Text RSS after the browser has executed Javascript. On this particular page that means, when Full-Text RSS gets the HTML, it includes the elements that were added by Javascript, including the image:
Maybe that’s what happens with Wallabag too.
I can’t actually remember if the browser strips the <noscript> tags when the rendered HTML is accessed via Javascript. If it does, then adding the replace_string rules above will work fine for both cases. But if it doesn’t, you may see duplicated images (both img tags now preserved). I’ve seen that on certain sites where we’ve tried to fix lazy loading via site config files. In such cases you may end up having to add extra rules to detect when the HTML being parsed has signs of both Javascript rendered images and <noscript> replacement. Can be a bit messy 
1 Like
Thank you so much for the very detailed explanation @fivefilters and the suggestion for Firefox, I didn’t know it yet.
So now I could manage to have the images in FTR and stripping the resulting double images in Wallabag. Hopefully that will do in P2K as well.
1 Like
Thanks for the changes, @HolgerAusB! Will test both later and let you know