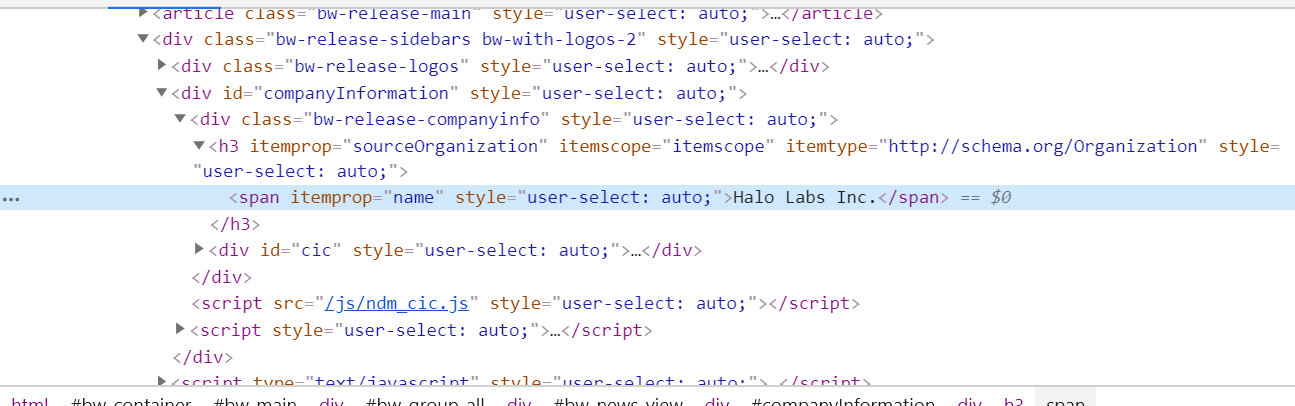
I’m trying to use the custom patterns to get the author name from press releases posted on Business Wire. However, I am having trouble with this specific website.
The code appears in Chrome developer console, but I can’t find it in the html source code. So I am assuming the content is loaded dynamically after the initial page load. Is there a way to scrape this?
I tried this author: //h3[@itemprop='sourceOrganization']
No easy way to scrape that with Full-Text RSS at the moment. It’s important to look at the source HTML to verify the element you want to target was actually served up as part of the main HTML response and not, as in this case, inserted after Javascript execution. One easy way to do that is to use our Site Config creator to load a page: http://siteconfig.fivefilters.org as that will ignore Javascript. Alternatively you can disable Javascript in your browser temporarily and then use the Chrome developer inspector.
In the future we’ll have an option to allow users to have extraction occur on pages after JS has been executed, but no estimate as to when that will be ready.
In the future we’ll have an option to allow users to have extraction occur on pages after JS has been executed, but no estimate as to when that will be ready.
Biggest wish by far! I am no using ProxyCrawl to get data from. As a suggestion: I like that they have two parameters: the ajax_wait (let the page render) and the page_wait (which will just wait x seconds after the page is loaded). I find I need both approaches to tackle Angular and Raven websites.
Additional tip for the OP: sometimes it helps if you set http_header(user-agent): Googlebot-News Some site the serve a more crawler friendly version of the page.
Thanks for the suggestions, Rene. I’m curious, are you using ProxyCrawl separately from Full-Text RSS or have you found a way to combine the two? We were looking into proxy services that offered a headless browser layer, to get results of JS processing in the regular proxy response. That kind of service might work with Full-Text RSS’s proxy support, but the delays involved might be too much of a barrier. In any case, we didn’t find anything like that at the time. And I’m not sure if the service you describe offers that or requires use of its own API to request JS pages.
We use it separately for when FTRSS can’t handle the individual page retrieval.
We initially coded something ourselves with a open source headless browser (need to look up what that was). Then used Splash (part of of ScrapingHub), but doesn’t behave well, too complicated, too hard to find out what goes wrong. However, ProxyCrawl API hasn’t failed us yet, most pages come back in about 4 seconds, which is quite acceptable to us.
As an intermediate suggestion, perhaps a parameter in FTRSS where you could indicate a proxy url to use? This url can then be prepended to the individual page requests. Would work fine for splash, proxycrawl, etc.
Thanks Rene, good to know. We’re thinking more about proxies and headless browsers to tackle some of the trickier cases users report.
As for proxy use as things stand, it’s possible to add proxy servers to a self-hosted copy of Full-Text RSS using its config file. And once added in the config, it’s possible to select a specific proxy server to use in a request using the proxy parameter. Is that something you’ve tried?