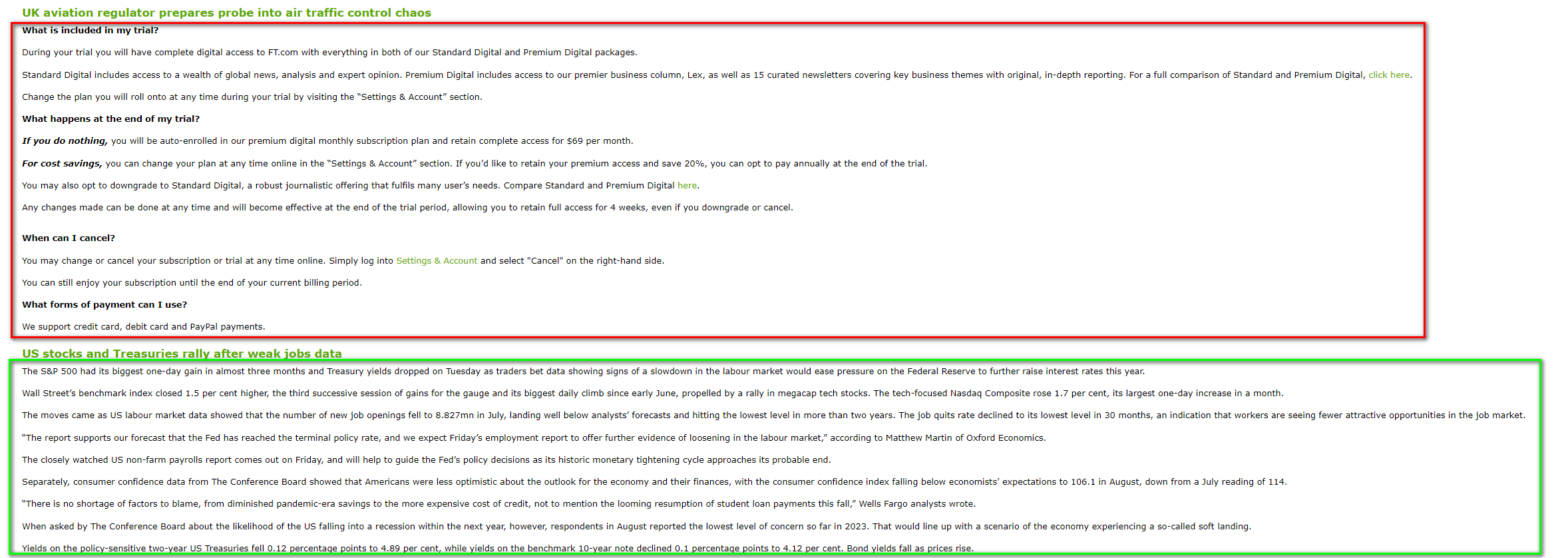
Hello, I’m using this feed from the Financial Times (<![CDATA[News Feed]]>) and it has a weird behavior. Some articles get extracted properly (green rectangle in the screenshot), while others (red rectangle) show the paywall content.
That is weird! While trying this several times I sometimes get the subscription warning and a few minutes later I get the full content of the very same article.
It seems that they deliver several alternating html-formats. Even when opening an article with catched full-text, I don’t find text from the excerpt in the original source.
@fabio If you are a subscriber you can try to export cookies while logged-in to FT and put this in your ft.com.txt (self-hoster only): http_header(cookie): cookiename=content
or multiple cookies: http_header(cookie): name1=content1; name2=content2
I was doing some digging and appears that the FT servers providing different responses depending on what the cookie contents are. If the cookie is “right”, it returns the actual article content, whereas if it is just a “visitor” it returns just the paywall HTML without the article text…
Pls bear with me, as I dont have a very good understanding of how the site patterns work or their capabilities… Is there some way to have the site pattern “fake” a good cookie, e.g. by maybe faking a valid referrer, or some other technique…?
Btw here’s a screenshot of the the same FT article. On the left side, it uses the paywall Chrome extension that allows the full article to load, on the right you can see it loading in an incognito tab. I tried to highlight (green rectangles) the main differences I saw
Use that one from your own test with your Browser Extension. I don’t know, if this expires, if you have an rss aggregator which automatically get new articles
I see, just checked it. The referer is the problem, that makes it worse. And just to make shure I explained it right:
Go to ft.com in your Browser, use your extension, load one article in fulltext, extract the 36-digit cookie with the name FTAllocation and paste that value behind the =, without hyphens. This is just an example, you need to paste your own value: http_header(cookie): FTAllocation=12345678-9abc-def0-1234-56789abcdef0
where I just see, that this 36-digit value seem to be the same as in the article URL itself. But not all of them can be used universal for all articles.
it works on first tests here, and would make the site_config universal.
It should take the URL, e.g. www.ft.com/content/f47fafd0-079d-4bc9-bbf5-19e55d5649ad and extract the last part to set cookie to: FTAllocation=f47fafd0-079d-4bc9-bbf5-19e55d5649ad
EDIT:
I think it’s not valid code, but FT seems to accept nearly every content on that cookie-name (at the moment). Is there a way to dynamically set a cookie based on parts of the URL or from the html-code? Last one would mean, that the page has to be loaded twice, I think.
It’s weird, the cookie approach works for SOME articles, but others continue hitting the paywall.
Isn’t it strange that the same server will behave differently depending on which article you’re trying to get access to…? Some articles get extracted just fine regardless of any cookies being set, while others get the paywall response from the server…

{kind=link}