Next question:
While parsing some sites I receive “[unable to retrieve full-text content]” message.
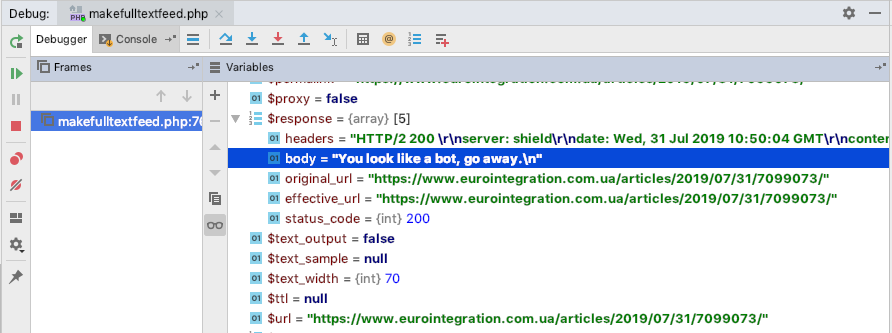
I have debugged the script and on the extraction section $response->body contains message “You look like a bot, go away.”
Thus, the server recognizes the script as a bot. I tried to use a proxy and set various values of http_header(user-agent): in config files without any result.
Can you help me to solve the issue? Sites are critical for my project 
Examples:
https://www.eurointegration.com.ua/articles/2019/07/31/7099073/
https://vybory.pravda.com.ua/news/2019/07/23/7150055/
Thanks a lot for a fast reply.
Added:
Probably the problem is in a multiple access to the page by script and server software (i.e. file2ban) block access to pages. Maybe you’ll change the script to bypass such behavior?