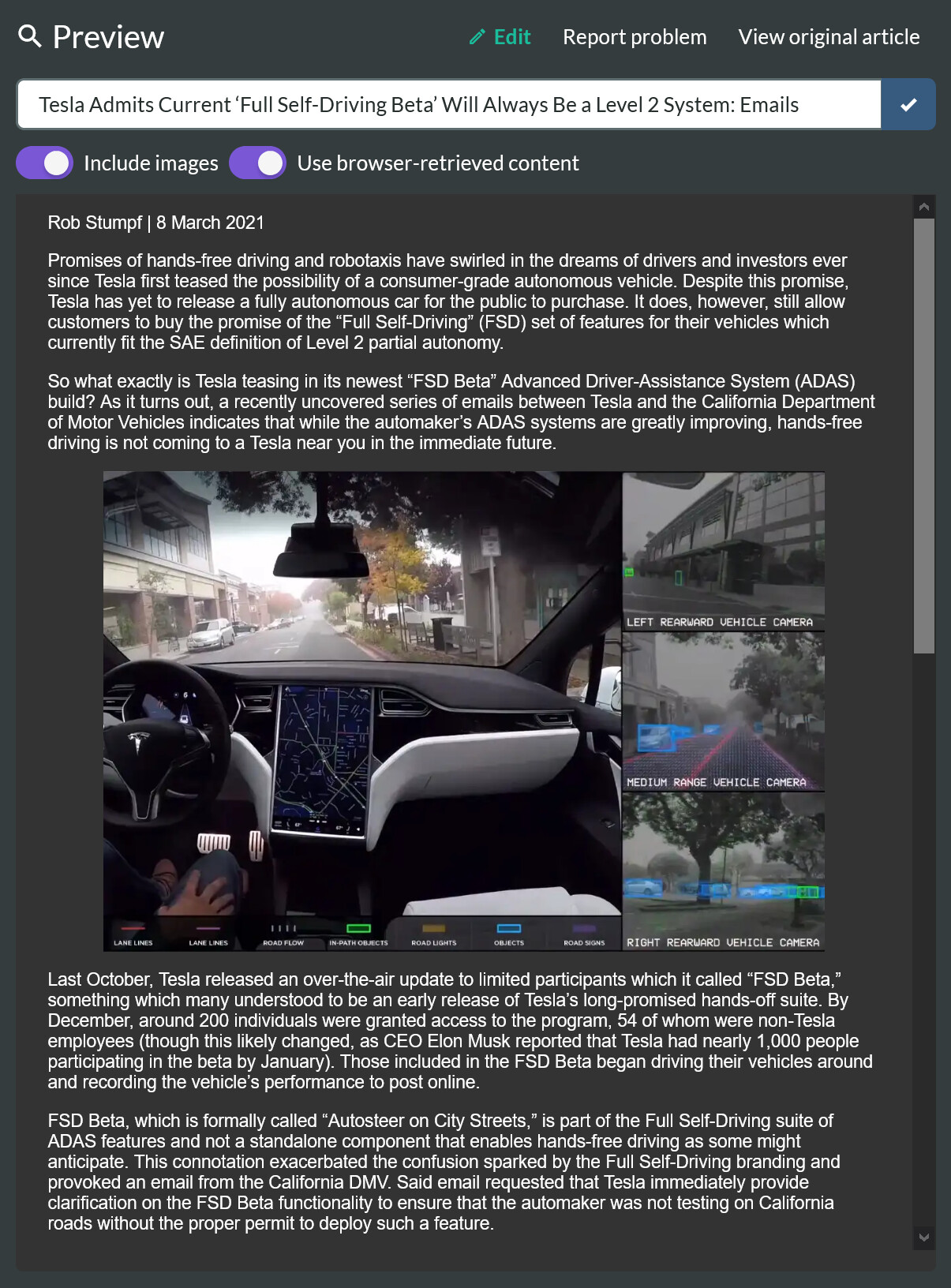
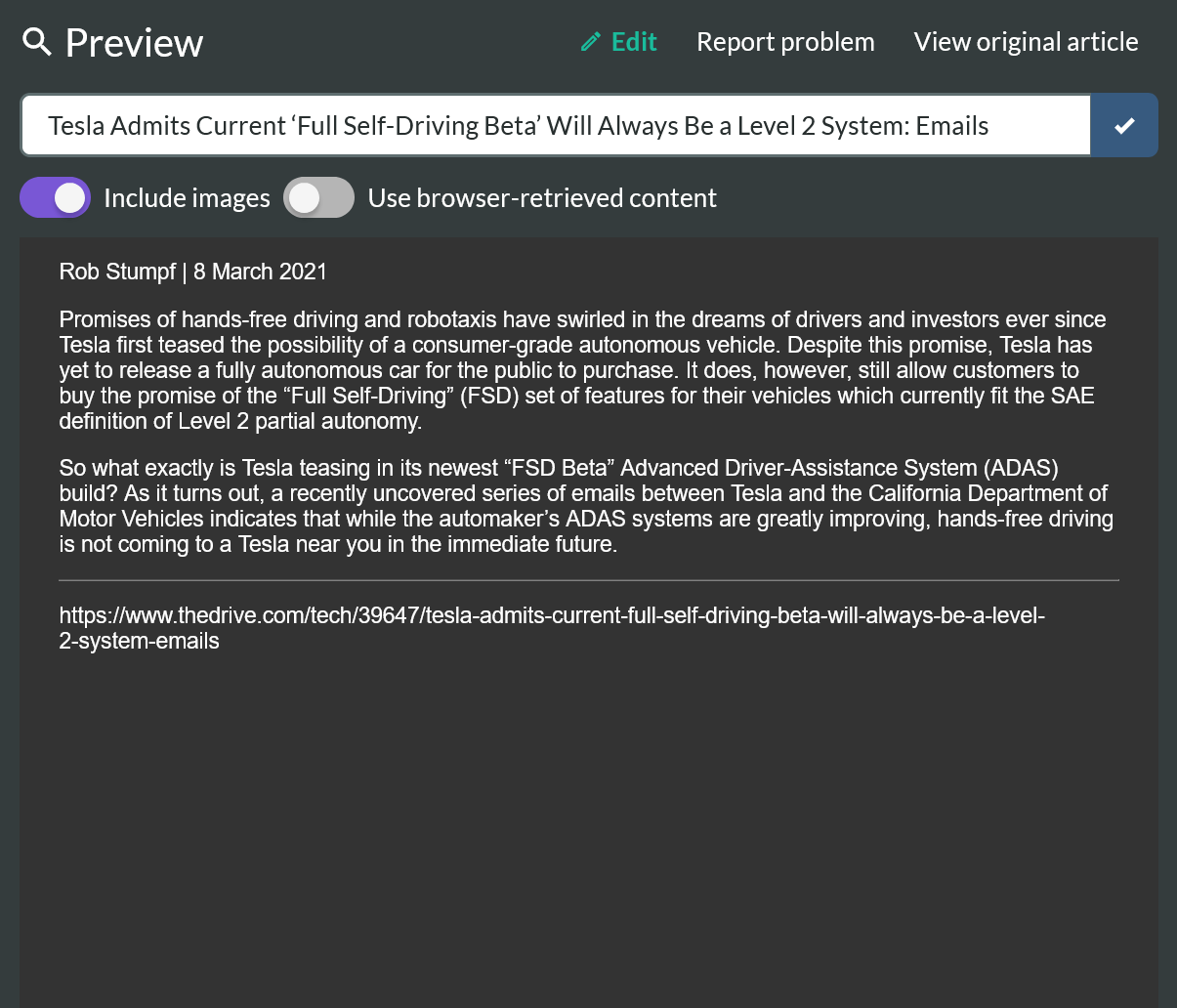
Hi there, thanks for the problem report, and no problem at all about the review.
We’ve now fixed extraction for this site, so future articles you send from this site via the Push to Kindle app should be processed okay. (The changes can take up to an hour to take effect.)
If you’re curious about the issue that caused the extraction problem: thedrive.com currently use invalid HTML in all its article sections, see below for example:
The red parts (highlighted by Firefox in its source view) indicate invalid HTML tags in that section of the article.
Normally invalid HTML tags aren’t a problem for our parser, but these tags indicate the start and end of a document. Our parser extracts them, but during cleanup, the article gets cut short when the </body></html> tags are encountered at the end of the first text section.
If you use our browser-based Push to Kindle extension, we process the HTML after your browser has treated it, so these tags are automatically removed by the browser before it reaches Push to Kindle, so the content gets through fine.
But when you use the app, we make a server request for the content, which brings with it the invalid HTML tags. So before we applied the fix you would have seen something like this due to the problem above.
On the whole most pages should work the same in both modes, but there are some that will work better in browser-retrieved mode. At the moment to use the browser-retrieved mode via mobile, you’ll have to use our bookmarklet here (a little clunkier to to set up and use compared to the app): Push to Kindle bookmarklet - FiveFilters.org
In the future we hope to bring similar functionality to the app too, but currently Android does not allow us to pull in HTML from the browser directly.